
آموزش Souping کردن صفحه در Beautiful Soup

آموزش Souping کردن صفحه در Beautiful Soup
در این درس از مجموعه آموزش برنامه نویسی سایت سورس باران، به آموزش Souping کردن صفحه در Beautiful Soup خواهیم پرداخت.
پیشنهاد ویژه : آموزش طراحی وب سایت با پایتون
در مثال کد قبلی، ما سند را از طریق سازنده زیبا با استفاده از روش رشته تجزیه می کنیم. روش دیگر این است که سند را از طریق فایل باز، باز کنید.
|
1 2 3 4 |
from bs4 import BeautifulSoup with open("example.html") as fp: soup = BeautifulSoup(fp) soup = BeautifulSoup("<html>data</html>") |
ابتدا سند به یونی کد تبدیل می شود و موجودیت های HTML به کاراکتر های یونیکد تبدیل می شوند: </ p>
|
1 2 3 4 |
import bs4 html = '''<b>tutorialspoint</b>, <i>&web scraping &data science;</i>''' soup = bs4.BeautifulSoup(html, 'lxml') print(soup) |
خروجی
|
1 |
<html><body><b>tutorialspoint</b>, <i>&web scraping &data science;</i></body></html> |
BeautifulSoup سپس داده ها را با استفاده از تجزیه کننده HTML تجزیه می کند یا صریحاً به آنها می گویید با استفاده از تجزیه کننده XML تجزیه کنند.
ساختار درخت HTML
قبل از بررسی اجزای مختلف یک صفحه HTML، ابتدا ساختار درخت HTML را درک می کنیم.
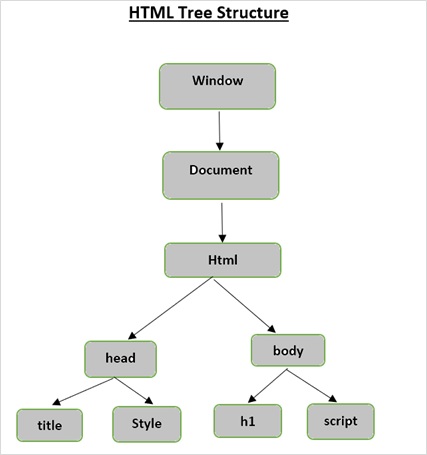
عنصر ریشه ای در درخت سند html است که می تواند پدر و مادر ، فرزند و خواهر و برادر داشته باشد و این با توجه به موقعیت آن در ساختار درخت تعیین می شود. برای جابجایی در میان عناصر، ویژگی ها و متن HTML ، باید در میان گره های ساختار درخت خود حرکت کنید.
بگذارید فرض کنیم صفحه وب همانطور که در زیر نشان داده شده است –
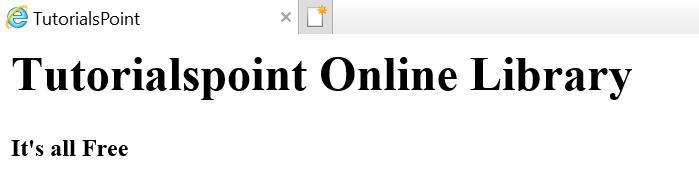
که به یک سند html به شرح زیر ترجمه می شود –
|
1 |
<html><head><title>TutorialsPoint</title></head><h1>Tutorialspoint Online Library</h1><p<<b>It's all Free</b></p></body></html> |
این به معنای ساده است، برای سند بالاتر از HTML ، ما یک ساختار درخت HTML داریم به شرح زیر –
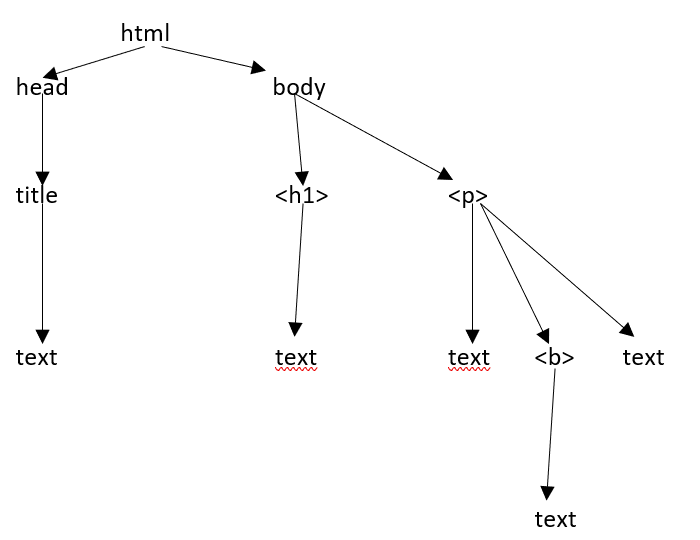



.svg)
دیدگاه شما