
مبانی یادگیری ماشین با پایتون

مبانی یادگیری ماشین با پایتون
در این درس از مجموعه آموزش برنامه نویسی سایت سورس باران، به مبانی یادگیری ماشین با پایتون خواهیم پرداخت.
پیشنهاد ویژه : پکیج آموزش پروژه محور پایتون
ما در “عصر داده” زندگی می کنیم که با قدرت محاسباتی بهتر و منابع ذخیره سازی بیشتر ارتباط تنگانگی دارد. این داده ها یا اطلاعات روز به روز در حال افزایش است، اما چالش واقعی این است که تمام داده ها را درک کنیم. مشاغل و سازمان ها سعی دارند با ساختن سیستم های هوشمند با استفاده از مفاهیم و روش های علم داده، داده کاوی و یادگیری ماشین با آن مقابله کنند. در این میان یادگیری ماشینی مهیج ترین رشته علوم رایانه است. اشتباه نخواهد بود اگر ما یادگیری ماشین را کاربرد و علم الگوریتم هایی می دانیم که داده ها را حس می کنند.
یادگیری ماشینی چیست؟
یادگیری ماشینی (ML) آن رشته از علوم کامپیوتر است که به کمک آن سیستم های رایانه ای می توانند داده ها را دقیقاً به همان روشی که انسان می سازد ، فراهم کنند.
به عبارت ساده، ML نوعی هوش مصنوعی است که با استفاده از الگوریتم یا روش، الگوهای داده های خام را استخراج می کند. تمرکز اصلی ML این است که به سیستم های رایانه ای بدون اینکه به طور صریح برنامه ریزی شده یا مداخله انسانی انجام شود ، از تجربه یاد بگیرند.
نیاز به یادگیری ماشین
در این لحظه، انسان ها باهوش ترین و پیشرفته ترین گونه های روی زمین هستند زیرا می توانند مشکلات پیچیده را فکر کنند، ارزیابی و حل کنند. از طرف دیگر هوش مصنوعی هنوز در مرحله اولیه خود است و از بسیاری جنبه ها از هوش انسان پیشی نمی گیرد. سپس سوال این است که چه نیازی به یادگیری ماشین وجود دارد؟ مناسب ترین دلیل برای انجام این کار ، “تصمیم گیری بر اساس داده ها ، با کارایی و مقیاس” است.
به تازگی، سازمان ها سرمایه گذاری زیادی در فناوری های جدید مانند هوش مصنوعی، یادگیری ماشین و یادگیری عمیق می کنند تا اطلاعات کلیدی را برای انجام چندین کار در دنیای واقعی و حل مشکلات از داده ها دریافت کنند. ما می توانیم آن را تصمیماتی مبتنی بر داده بگیریم که توسط ماشین آلات گرفته می شود، به ویژه برای خودکار کردن فرآیند. این تصمیمات داده محور را می توان به جای استفاده از منطق برنامه نویسی ، در مشکلاتی که به طور ذاتی قابل برنامه ریزی نیستند ، استفاده کرد. واقعیت این است که ما نمی توانیم بدون هوش انسانی کار کنیم ، اما جنبه دیگر این است که همه ما باید مشکلات دنیای واقعی را با کارایی در مقیاس عظیم حل کنیم. به همین دلیل است که نیاز به یادگیری ماشین وجود دارد.
چرا و چه موقع باید یادگیری ماشین را یاد گرفت؟
ما قبلاً در مورد نیاز به یادگیری ماشین بحث کردیم، اما سوال دیگری مطرح می شود که در چه سناریوهایی باید ماشین را یاد بگیریم؟ شرایط مختلفی وجود دارد که ما به یادگیری ماشین نیاز داریم تا تصمیمات مبتنی بر داده را با کارایی و در مقیاس عظیم اتخاذ کنیم. موارد زیر برخی از چنین شرایطی است که یادگیری ماشین در آنها موثرتر خواهد بود –
فقدان تخصص انسانی
اولین سناریویی که ما می خواهیم یادگیری ماشین و تصمیم گیری های مبتنی بر داده تصمیم بگیرد، می تواند حوزه ای باشد که در آن کمبود تخصص انسانی وجود دارد. نمونه ها می توانند پیمایش در مناطق ناشناخته یا سیارات فضایی باشند.
سناریوهای پویا
برخی از سناریوها از نظر ماهیت پویا هستند، یعنی با گذشت زمان تغییر می کنند. در صورت وجود این سناریوها و رفتارها، ما می خواهیم دستگاهی یاد بگیرد و تصمیمات مبتنی بر داده را اتخاذ کند. برخی از این مثالها می تواند اتصال به شبکه و در دسترس بودن زیرساخت ها در یک سازمان باشد.
مشکل در ترجمه تخصص ها به وظایف محاسباتی
حوزه های مختلفی می تواند وجود داشته باشد که بشر در آن تخصص داشته باشد. با این حال، آنها قادر به ترجمه این تخصص به کارهای محاسباتی نیستند. در چنین شرایطی ما یادگیری ماشین می خواهیم. مثالها می توانند حوزه های تشخیص گفتار ، وظایف شناختی و غیره باشند.
مدل یادگیری ماشین
قبل از بحث در مورد مدل یادگیری ماشین، ما باید تعریف رسمی زیر را که از استاد میچل ارائه شده است درک کنیم –
“گفته می شود که یک برنامه رایانه ای با توجه به برخی از کلاسهای T و اندازه گیری عملکرد P از تجربه E یاد می گیرد، اگر عملکرد آن در T در اندازه گیری با P با تجربه E بهبود یابد.”
تعریف فوق اساساً بر روی سه پارامتر متمرکز است، همچنین مولفه های اصلی هر الگوریتم یادگیری ، یعنی Task (T)، عملکرد (P) و تجربه (E) است. در این زمینه، ما می توانیم این تعریف را ساده کنیم به عنوان –
ML یک رشته هوش مصنوعی است که متشکل از الگوریتم های یادگیری است که –
- بهبود عملکرد آنها (P)
- هنگام اجرای برخی کارها (T)
- با گذشت زمان با تجربه (E)
بر اساس موارد فوق ، نمودار زیر یک مدل یادگیری ماشین را نشان می دهد –
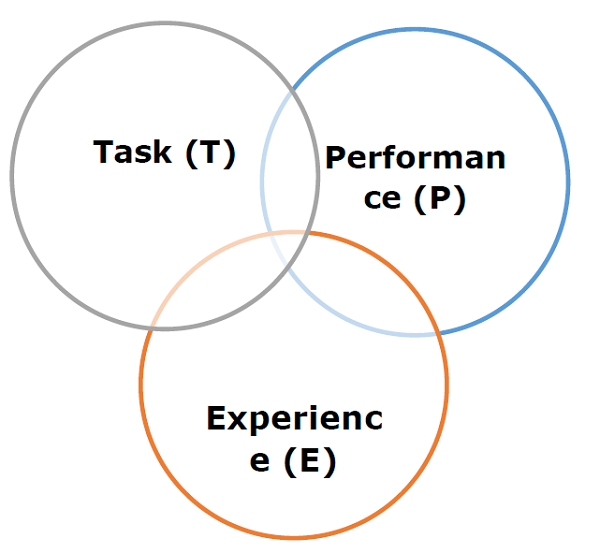
بگذارید اکنون با جزئیات بیشتری در مورد آنها بحث کنیم –
وظیفه (T)
از منظر مسئله، ممکن است وظیفه T را به عنوان مسئله دنیای واقعی که باید حل شود، تعریف کنیم. مشکل می تواند چیزی مانند یافتن بهترین قیمت خانه در یک مکان خاص یا یافتن بهترین استراتژی بازاریابی و غیره باشد. از طرف دیگر، اگر در مورد یادگیری ماشین صحبت کنیم، تعریف وظیفه متفاوت است زیرا حل وظایف مبتنی بر ML توسط رویکرد برنامه نویسی مرسوم.
وظیفه T زمانی گفته می شود که یک کار مبتنی بر ML باشد که براساس فرآیند باشد و سیستم برای کار در نقاط داده دنبال کند. مثالهای کارهای مبتنی بر ML طبقه بندی، رگرسیون، حاشیه نویسی ساختاری، خوشه بندی، رونویسی و غیره است.
تجربه (E)
همانطور که از نامش پیداست، این دانش به دست آمده از نقاط داده ای است که به الگوریتم یا مدل ارائه شده است. پس از ارائه مجموعه داده، مدل به صورت تکراری اجرا می شود و برخی از الگوی ذاتی را یاد می گیرد. یادگیری بدست آمده بدین ترتیب تجربه (E) نامیده می شود. با قیاس یادگیری انسان، می توانیم به این وضعیت فکر کنیم که در آن انسان در حال یادگیری است یا از ویژگی های مختلف مانند موقعیت ، روابط و غیره تجربه می کند. یادگیری تحت نظارت ، بدون نظارت و تقویت برخی از راه های یادگیری یا کسب تجربه است. تجربه حاصل از مدل یا الگوریتم ML برای حل وظیفه T استفاده خواهد شد.
عملکرد (P)
یک الگوریتم ML قرار است وظیفه خود را انجام دهد و با گذشت زمان تجربه کسب کند. معیاری که نشان می دهد الگوریتم ML طبق انتظار عمل می کند یا خیر عملکرد آن است . P اساساً یک معیار کمی است که نحوه عملکرد یک مدل را بیان می کند، T ، با استفاده از تجربه خود ، E. معیارهای زیادی وجود دارد که به درک عملکرد ML کمک می کند ، مانند نمره دقت ، نمره F1 ، ماتریس سردرگمی ، دقت ، یادآوری ، حساسیت و غیره
چالش های یادگیری ماشین
در حالی که یادگیری ماشین به سرعت در حال پیشرفت است و با امنیت سایبری و اتومبیل های مستقل گام های قابل توجهی برداشته است، به طور کلی این بخش از هوش مصنوعی هنوز مسیری طولانی را سپری می کند. دلیل این امر این است که ML نتوانسته است بر چالش های مختلف غلبه کند. چالش هایی که ML در حال حاضر با آن روبرو است –
کیفیت داده ها – داشتن داده های با کیفیت خوب برای الگوریتم های ML یکی از بزرگترین چالش ها است. استفاده از داده های بی کیفیت منجر به مشکلات مربوط به پیش پردازش داده ها و استخراج ویژگی ها می شود.
وقت گیر – چالش دیگری که مدل های ML با آن روبرو هستند مصرف زمان به ویژه برای دستیابی به داده ها ، استخراج و بازیابی ویژگی ها است.
کمبود افراد متخصص – از آنجا که فناوری ML هنوز در مرحله ابتدایی است ، در دسترس بودن منابع متخصص کار سختی است.
عدم وجود هدف مشخص برای تنظیم مشکلات تجاری – نداشتن هدف مشخص و مشخص برای مشکلات تجاری چالش اصلی دیگری برای ML است زیرا این فناوری هنوز آنقدر بالغ نشده است.
مسئله نصب – اگر مدل بیش از حد یا کمبود باشد، نمی توان آن را به خوبی برای مشکل نشان داد.
ابعاد – چالش دیگری که مدل ML با آن روبرو است ، ویژگی های بیش از حد نقاط داده است. این می تواند یک مانع واقعی باشد.
مشکل در استقرار – پیچیدگی مدل ML استقرار در زندگی واقعی را کاملاً دشوار می کند.
کاربردهای یادگیری ماشین
یادگیری ماشینی سریع ترین فناوری است و به گفته محققان ما در سال طلایی هوش مصنوعی و ML هستیم. برای حل بسیاری از مشکلات پیچیده دنیای واقعی استفاده می شود که با رویکرد سنتی قابل حل نیست. در زیر برخی از برنامه های ML در دنیای واقعی آورده شده است –
- تجزیه و تحلیل احساسات
- تحلیل احساسات
- شناسایی و پیشگیری از خطا
- پیش بینی و پیش بینی هوا
- تحلیل و پیش بینی بازار سهام
- سنتز گفتار
- تشخیص گفتار
- تقسیم بندی مشتری
- تشخیص اشیا
- تشخیص تقلب
- جلوگیری از کلاه برداری
- پیشنهاد محصولات به مشتری در خرید آنلاین.



.svg)
دیدگاه شما