
آموزش متدها در یادگیری ماشین با پایتون

آموزش متدها در یادگیری ماشین با پایتون
در این درس از مجموعه آموزش برنامه نویسی سایت سورس باران، به آموزش متدها در یادگیری ماشین با پایتون خواهیم پرداخت.
پیشنهاد ویژه : پکیج آموزش پروژه محور پایتون
الگوریتم ها، تکنیک ها و متد های مختلف ML وجود دارد که می توان با استفاده از داده ها مدل هایی برای حل مشکلات زندگی واقعی ساخت. در این فصل ، ما می خواهیم انواع مختلفی از روش ها را مورد بحث قرار دهیم.
انواع مختلف متدها در یادگیری ماشین با پایتون
در زیر روش های مختلف ML بر اساس برخی از دسته های گسترده وجود دارد –
براساس نظارت انسان
در فرایند یادگیری، برخی از روش هایی که بر اساس نظارت انسان است به شرح زیر است –
یادگیری تحت نظارت
الگوریتم ها یا روش های یادگیری تحت نظارت معمول ترین الگوریتم های ML هستند. این روش یا الگوریتم یادگیری، نمونه داده را به عنوان مثال داده های آموزش و خروجی مربوط به آن، یعنی لیبل ها یا پاسخ ها با هر نمونه داده در طول فرایند آموزش ، می گیرد.
هدف اصلی الگوریتم های یادگیری تحت نظارت، یادگیری ارتباط بین نمونه های داده ورودی و خروجی های مربوطه پس از انجام چندین نمونه داده آموزش است.
به عنوان مثال،
- x: متغیرهای ورودی و
- Y: متغیر خروجی
اکنون، یک الگوریتم برای یادگیری عملکرد نگاشت از ورودی به خروجی به شرح زیر اعمال کنید –
Y = f (x)
اکنون، هدف اصلی تقریبی تابع نگاشت به خوبی است که حتی وقتی داده ورودی جدید (x) داریم ، می توانیم متغیر خروجی (Y) را برای آن داده ورودی جدید به راحتی پیش بینی کنیم.
نظارت نامیده می شود زیرا کل فرآیند یادگیری همانطور که توسط یک معلم یا ناظر نظارت می شود می تواند فکر شود. نمونه هایی از الگوریتم های یادگیری ماشین تحت نظارت شامل درخت تصمیم، جنگل تصادفی، KNN، رگرسیون لجستیک و غیره است.
براساس وظایف ML، الگوریتم های یادگیری نظارت شده را می توان به دو کلاس گسترده زیر تقسیم کرد –
- طبقه بندی
- رگرسیون
طبقه بندی
هدف اصلی وظایف مبتنی بر طبقه بندی پیش بینی برچسب ها یا پاسخ های طبقه بندی شده برای داده های ورودی داده شده است. خروجی براساس آنچه مدل در مرحله آموزش آموخته است، خواهد بود. همانطور که می دانیم پاسخهای خروجی طبقه بندی به معنای مقادیر نامرتب و گسسته است، بنابراین هر پاسخ خروجی به یک کلاس یا دسته خاص تعلق خواهد داشت. ما همچنین در درس های آینده طبقه بندی و الگوریتم های مرتبط را به تفصیل بحث خواهیم کرد.
رگرسیون
هدف اصلی وظایف مبتنی بر رگرسیون پیش بینی برچسب های خروجی یا پاسخ هایی است که مقادیر عددی ادامه دار برای داده های ورودی داده شده است. خروجی براساس آنچه مدل در مرحله آموزش خود آموخته است، خواهد بود. اساساً ، مدلهای رگرسیونی از ویژگیهای داده ورودی (متغیرهای مستقل) و مقادیر خروجی عددی پیوسته مربوطه (متغیرهای وابسته یا نتیجه) برای یادگیری ارتباط خاص بین ورودیها و خروجیهای مربوطه استفاده می کنند. ما در فصل های بعدی نیز رگرسیون و الگوریتم های مرتبط را به تفصیل بحث خواهیم کرد.
یادگیری بدون نظارت
همانطور که از نامش پیداست ، این در مقابل روشهای ML یا الگوریتمهای تحت نظارت است ، این بدان معناست که در الگوریتمهای یادگیری ماشین بدون نظارت ما هیچ ناظری برای ارائه هر نوع راهنمایی نداریم. الگوریتم های یادگیری بدون نظارت در سناریویی که ما نمی توانیم مانند الگوریتم های یادگیری تحت نظارت ، از داشتن داده های آموزش از قبل برچسب خورده استفاده کنیم ، می خواهیم الگوی مفیدی را از داده های ورودی استخراج کنیم.
به عنوان مثال، می توان آن را به صورت زیر درک کرد –
فرض کنید ما داریم –
x: متغیرهای ورودی، پس متغیر خروجی متناظر وجود ندارد و الگوریتم ها باید الگوی جالب داده ها را برای یادگیری کشف کنند.
نمونه هایی از الگوریتم های یادگیری ماشین بدون نظارت شامل خوشه بندی K-means K-نزدیکترین همسایگان و غیره
براساس وظایف ML، الگوریتم های یادگیری بدون نظارت را می توان به کلاسهای گسترده زیر تقسیم کرد –
- خوشه بندی
- اتحاد
- کاهش ابعاد
خوشه بندی
روشهای خوشه بندی یکی از مفیدترین روشهای ML بدون نظارت است. این الگوریتم ها برای یافتن شباهت و همچنین الگوهای رابطه در بین نمونه های داده استفاده می شدند و سپس این نمونه ها را بر اساس ویژگی ها در گروه هایی با شباهت قرار می دادند. نمونه خوشه بندی در دنیای واقعی این است که مشتریان را بر اساس رفتار خرید آنها دسته بندی کنید.
اتحاد
یکی دیگر از روشهای مفید بدون نظارت یادگیری ماشین، اتحاد است که برای تجزیه و تحلیل مجموعه داده های بزرگ برای یافتن الگوهایی استفاده می شود که بیشتر نشان دهنده روابط جالب بین موارد مختلف است. همچنین به عنوان Association Rule Mining یا تحلیل سبد بازار که عمدتا برای تجزیه و تحلیل الگوی خرید مشتری استفاده می شود ، نامیده می شود.
کاهش ابعاد
این روش ML بدون نظارت برای کاهش تعداد متغیرهای ویژگی برای هر نمونه داده با انتخاب مجموعه ای از ویژگی های اصلی یا نماینده استفاده می شود. در اینجا سوالی مطرح می شود این است که چرا ما باید ابعاد را کاهش دهیم؟ دلیل این مسئله مشکل پیچیدگی فضای ویژگی ها است که وقتی شروع به تجزیه و تحلیل و استخراج میلیون ها ویژگی از نمونه های داده می کنیم، بوجود می آید. این مشکل به طور کلی به “curse of dimensionality” اشاره دارد. PCA (تجزیه و تحلیل مولفه اصلی) ، نزدیکترین همسایگان K و تجزیه و تحلیل تفکیک برخی از الگوریتم های معروف برای این منظور هستند.
تشخیص ناهنجاری
این روش ML بدون نظارت برای کشف وقایع نادر یا مشاهداتی که عموماً اتفاق نمی افتد استفاده می شود. با استفاده از دانش آموخته شده، روش های تشخیص ناهنجاری قادر به تمایز بین یک داده غیر عادی یا یک داده عادی هستند. برخی از الگوریتم های نظارت نشده مانند خوشه بندی ، KNN می تواند ناهنجاری ها را براساس داده ها و ویژگی های آن تشخیص دهد.
یادگیری نیمه نظارت شده – متدها در یادگیری ماشین با پایتون
این نوع الگوریتم ها یا روش ها نه کاملاً نظارت می شوند و نه کاملاً تحت نظارت هستند. آنها اساساً بین این دو روش یادگیری تحت نظارت و بدون نظارت قرار می گیرند. این نوع الگوریتم ها معمولاً از مولفه یادگیری تحت نظارت کوچک یعنی مقدار کمی داده حاشیه نویسی دارای برچسب از پیش برچسب زده شده و مولفه بزرگ یادگیری بدون نظارت ، یعنی تعداد زیادی داده بدون برچسب برای آموزش استفاده می کنند. ما می توانیم برای اجرای روشهای یادگیری نیمه نظارت شده ، هر یک از رویکردهای زیر را دنبال کنیم –
- روش اول و ساده ساخت مدل نظارت شده بر اساس مقدار کمی از داده های دارای برچسب و حاشیه نویسی و سپس ساخت مدل بدون نظارت با استفاده از همان مورد در مقادیر زیادی از داده های بدون برچسب برای بدست آوردن نمونه های دارای برچسب بیشتر است. حالا ، مدل را روی آنها آموزش دهید و مراحل را تکرار کنید.
- رویکرد دوم نیاز به تلاش های اضافی دارد. در این روش ، ما می توانیم ابتدا از روش های بدون نظارت برای خوشه بندی نمونه های داده مشابه ، حاشیه نویسی این گروه ها و سپس استفاده از ترکیبی از این اطلاعات برای آموزش مدل استفاده کنیم.
آموزش تقویت
این روشها متفاوت از روشهای مطالعه شده قبلی است و به ندرت نیز مورد استفاده قرار می گیرد. در این نوع الگوریتم های یادگیری، عاملی وجود دارد که می خواهیم آن را برای مدت زمانی آموزش دهیم تا بتواند با یک محیط خاص تعامل داشته باشد. نماینده مجموعه ای از استراتژی ها را برای تعامل با محیط پیروی می کند و سپس پس از مشاهده محیط نسبت به وضعیت فعلی محیط اقدام می کند. در زیر مراحل اصلی روشهای یادگیری تقویت وجود دارد –
- مرحله 1 – ابتدا، ما باید نیجنت را با چند استراتژی اولیه آماده کنیم.
- مرحله 2 – سپس محیط و وضعیت فعلی آن را مشاهده کنید.
- مرحله 3 – بعد، سیاست بهینه را با توجه به وضعیت فعلی محیط انتخاب کنید و اقدامات مهمی را انجام دهید.
- مرحله 4 – در حال حاضر، ایجنت می تواند پاداش یا مجازات مطابق با اقدام انجام شده در مرحله قبل دریافت کند.
- مرحله 5 – اکنون، در صورت نیاز، می توانیم استراتژی ها را به روز کنیم.
- مرحله 6 – سرانجام، مراحل 2-5 را تکرار کنید تا زمانی که نماینده یاد بگیرد و سیاست های بهینه را اتخاذ کند.
وظایف مناسب برای یادگیری ماشین
نمودار زیر نشان می دهد که چه نوع کار برای مشکلات مختلف ML مناسب است –
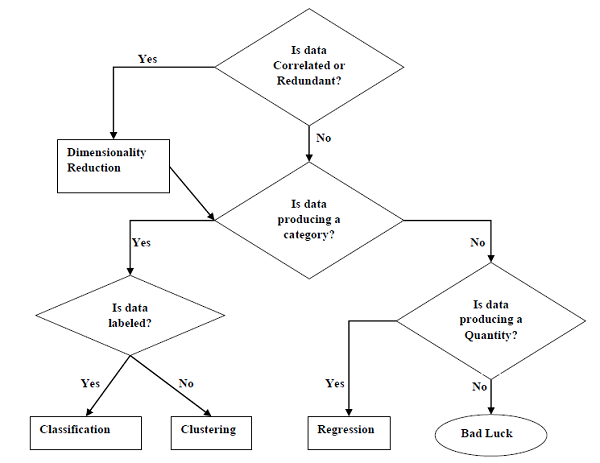
بر اساس توانایی یادگیری
در فرآیند یادگیری، موارد زیر برخی از روش های مبتنی بر توانایی یادگیری است –
یادگیری دسته ای
در بسیاری از موارد ما سیستمهای یادگیری ماشینی پایان به پایان داریم که در آنها باید با استفاده از کل دادههای آموزشی موجود، مدل را به صورت یکجا آموزش دهیم. به این نوع روش یا الگوریتم یادگیری، یادگیری دسته ای یا آفلاین گفته می شود، زیرا این یک روش یکبار مصرف است و مدل با داده ها در یک دسته واحد آموزش داده می شود. موارد زیر مراحل اصلی روشهای یادگیری دسته ای است –
- مرحله 1 – ابتدا باید تمام داده های آموزش را برای شروع آموزش مدل جمع آوری کنیم.
- مرحله 2 – اکنون، آموزش مدل را با ارائه اطلاعات کامل آموزش به صورت یکجا شروع کنید.
- مرحله 3 – بعد از اینکه نتیجه / عملکرد رضایت بخشی کسب کردید، فرآیند یادگیری / آموزش را متوقف کنید.
- مرحله 4 – سرانجام، این مدل آموزش دیده را در مرحله تولید قرار دهید. در اینجا ، خروجی برای نمونه داده جدید را پیش بینی می کند.
آموزش آنلاین متدها در یادگیری ماشین با پایتون
این کاملاً مخالف روشهای یادگیری دسته ای یا آفلاین است. در این روش های یادگیری، داده های آموزش به صورت دسته های افزایشی متعدد ، مینی بچ ها، به الگوریتم ارائه می شود. موارد زیر مراحل اصلی روشهای یادگیری آنلاین است –
- مرحله 1 – ابتدا، ما باید تمام داده های آموزش را برای شروع آموزش مدل جمع آوری کنیم.
- مرحله 2 – اکنون، آموزش مدل را با ارائه یک دسته کوچک از داده های آموزش به الگوریتم ، شروع کنید.
- مرحله 3 – بعد، ما باید مجموعه های کوچکی از داده های آموزش را به صورت چند مرحله ای به الگوریتم ارائه دهیم.
- مرحله 4 – از آنجا که مانند یادگیری دسته ای متوقف نخواهد شد ، بنابراین پس از ارائه اطلاعات کامل آموزش در دسته های کوچک ، نمونه های داده جدید را نیز در اختیار آن قرار دهید.
- مرحله 5 – سرانجام ، بر اساس نمونه های داده جدید ، یادگیری را برای مدتی ادامه خواهد داد.
بر اساس رویکرد تعمیم
در فرایند یادگیری، موارد زیر برخی از روش ها است که بر اساس رویکردهای تعمیم است –
یادگیری مبتنی بر نمونه
روش یادگیری مبتنی بر نمونه یکی از روشهای مفیدی است که با انجام تعمیم بر اساس داده های ورودی، مدلهای ML را ایجاد می کند. این در مقابل روشهای یادگیری قبلاً مورد مطالعه قرار گرفته است ، به روشی که این نوع یادگیری شامل سیستمهای ML و همچنین روشهایی است که از نقاط داده خام برای ترسیم نتایج برای نمونه های داده جدیدتر بدون ایجاد یک مدل صریح بر داده های آموزشی استفاده می کند.
به عبارت ساده ، یادگیری مبتنی بر نمونه اساساً با مشاهده نقاط داده ورودی شروع به کار می کند و سپس با استفاده از معیار تشابه ، نقاط داده جدید را تعمیم و پیش بینی می کند.
مدل مبتنی بر یادگیری
در روشهای یادگیری مبتنی بر مدل ، یک فرایند تکراری روی مدلهای ML که براساس پارامترهای مختلف مدل ساخته شده اند ، hyperparameters نامیده می شوند و در آنها داده های ورودی برای استخراج ویژگیها استفاده می شود ، صورت می گیرد. در این یادگیری، ابر پارامترها بر اساس تکنیک های مختلف اعتبارسنجی مدل بهینه می شوند. به همین دلیل است که می توان گفت روشهای یادگیری مبتنی بر مدل از رویکرد ML سنتی تر نسبت به تعمیم استفاده می کنند.



.svg)
دیدگاه شما