
آموزش کتابخانه ها در برنامه نویسی شی گرا در پایتون

آموزش کتابخانه ها در برنامه نویسی شی گرا در پایتون
در این درس از مجموعه آموزش برنامه نویسی سایت سورس باران، به آموزش کتابخانه ها در برنامه نویسی شی گرا در پایتون خواهیم پرداخت.
پیشنهاد ویژه : پکیج آموزش پایتون مختص بازار کار
ماژول درخواست های پایتون
درخواست ها یک ماژول پایتون است که یک کتابخانه HTTP زیبا و ساده برای پایتون است. با این کار می توانید انواع درخواست های HTTP را ارسال کنید. با استفاده از این کتابخانه می توانیم هدرها را اضافه کنیم، داده ها را تشکیل دهیم ، فایل ها و پارامترهای چند قسمتی و به داده های پاسخ دسترسی پیدا کنیم.
درخواست ها در پایتون یک ماژول توکار نیستند، بنابراین ابتدا باید آن را نصب کنیم.
می توانید آن را با اجرای دستور زیر در ترمینال نصب کنید –
|
1 |
pip install requests |
پس از نصب ماژول، می توانید با وارد کردن دستور زیر در پوسته پایتون، موفقیت آمیز بودن نصب را بررسی کنید.
|
1 |
import requests |
اگر نصب موفقیت آمیز بود، هیچ پیامی خطا مشاهده نمی کنید.
ایجاد درخواست GET
به عنوان مثال ما از “pokeapi” استفاده می کنیم
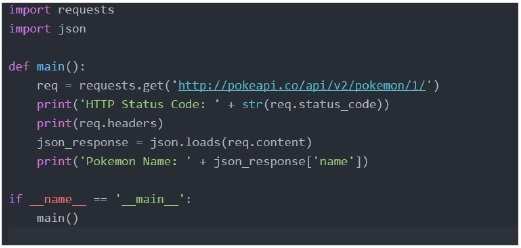
خروجی

ایجاد درخواست های POST
روش های کتابخانه ای را برای همه فعل های HTTP که در حال استفاده هستند درخواست می کند. اگر می خواهید یک درخواست POST ساده به یک نقطه پایانی API ارسال کنید ، می توانید این کار را به این صورت انجام دهید –
|
1 |
req = requests.post(‘http://api/user’, data = None, json = None) |
این دقیقاً همانند درخواست GET قبلی ما عمل می کند، اما دارای دو پارامتر کلید واژه اضافی است –
- داده هایی که می توان با یک دیکشنری، فایل یا بایت هایی که در بدنه HTTP درخواست POST ما ارسال می شود، پر شود.
- json که می تواند با یک شی json پر شود که در بدنه درخواست HTTP ما نیز ارسال می شود.
Pandas کتابخانه پایتون
Pandas یک کتابخانه پایتون منبع باز است که با استفاده از ساختارهای داده قدرتمند ، ابزار تجزیه و تحلیل داده ها با عملکرد بالا را ارائه می دهد. Pandas یکی از پرکاربردترین کتابخانه های پایتون در علم داده است. این برنامه عمدتا برای پردازش داده ها استفاده می شود و دلایل خوبی نیز وجود دارد: گروه قدرتمند و انعطاف پذیر از قابلیت ها.
ساخته شده بر روی بسته Numpy و ساختار داده کلیدی DataFrame نامیده می شود. این چارچوب های داده به ما امکان ذخیره و دستکاری داده های جداول را در ردیف مشاهدات و ستون های متغیرها می دهد.
روش های مختلفی برای ایجاد یک DataFrame وجود دارد. یک راه استفاده از دیکشنری است. به عنوان مثال –
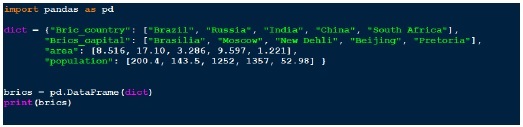
خروجی
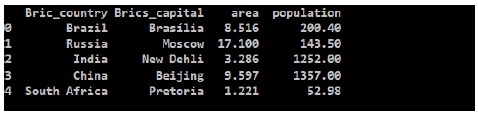
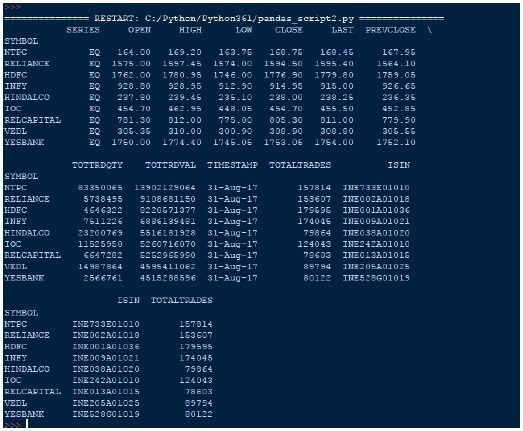
از خروجی می توانیم DataFrame جدید را مشاهده کنیم، Pandas یک کلید برای هر کشور به عنوان مقادیر عددی 0 تا 4 اختصاص داده است.
اگر می خواهیم به جای دادن نمایه سازی از 0 تا 4، مقادیر نمایه های متفاوتی داشته باشیم، کد کشور دو حرفی را بگویید، شما نیز می توانید این کار را به راحتی انجام دهید –
افزودن زیر یک خط در کد بالا، می دهد
brics.index = [‘BR’، ‘RU’، ‘IN’، ‘CH’، ‘SA’]
خروجی

نمایه سازی DataFrames
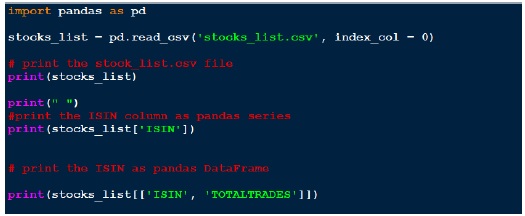
خروجی
کتابخانه Pygame در پایتون
Pygame یک کتابخانه منبع باز و چند پلتفرمی است که برای ایجاد برنامه های چند رسانه ای از جمله بازی ها استفاده می شود. این شامل گرافیک رایانه ای و کتابخانه های صوتی است که برای استفاده با زبان برنامه نویسی پایتون طراحی شده است. با Pygame می توانید بسیاری از بازی های جذاب را توسعه دهید. ‘
Pygame از ماژول های مختلفی تشکیل شده است که هر کدام با مجموعه ای از وظایف خاص سروکار دارند. به عنوان مثال، ماژول صفحه نمایش به پنجره و صفحه نمایش می پردازد ، ماژول draw عملکردهایی را برای ترسیم اشکال ارائه می دهد و ماژول کلید با صفحه کلید کار می کند. اینها تنها بخشی از ماژول های کتابخانه هستند.
خانه کتابخانه Pygame در https://www.pygame.org/news است
برای ایجاد یک برنامه Pygame، این مراحل را دنبال کنید –
وارد کردن کتابخانه Pygame
|
1 |
import pygame |
کتابخانه Pygame را شروع کنید
|
1 |
pygame.init() |
یک پنجره ایجاد کنید.
|
1 2 |
screen = Pygame.display.set_mode((560,480)) Pygame.display.set_caption(‘First Pygame Game’) |
در این مرحله ما تصاویر را بارگذاری می کنیم، صداها را بارگذاری می کنیم، موقعیت یابی اجسام را انجام می دهیم، برخی از متغیرهای حالت و غیره را تنظیم می کنیم.
شروع لوپ
این فقط یک حلقه است که ما به طور مداوم رویدادها را کنترل می کنیم، ورودی ها را بررسی می کنیم ، اشیاء را جابجا می کنیم و آنها را ترسیم می کنیم. هر تکرار حلقه را قاب می نامند.
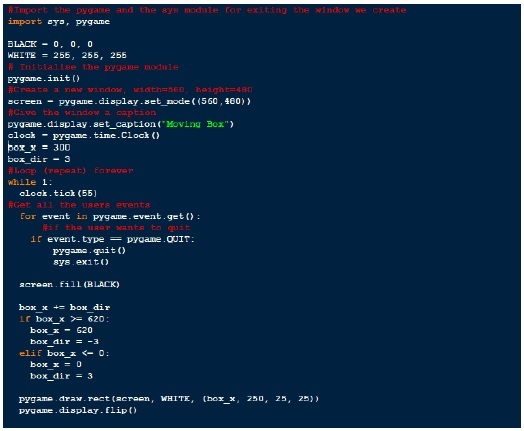
بیایید تمام منطق فوق را در یک برنامه زیر قرار دهیم ،
Pygame_script.py
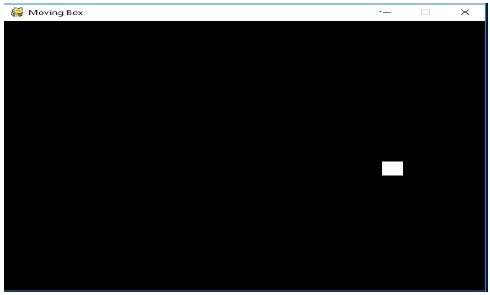
خروجی
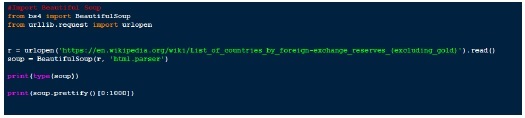
کتابخانه BeautifulSoup
ایده کلی پشت اسکرپ وب بدست آوردن داده های موجود در وب سایت و تبدیل آنها به فرمت قابل استفاده برای تجزیه و تحلیل است.
این یک کتابخانه پایتون برای بیرون کشیدن داده ها از فایل های HTML یا XML است. با تجزیه کننده مورد علاقه شما ، روشهای اصیل جهت یابی، جستجو و اصلاح درخت تجزیه را ارائه می دهد.
از آنجا که BeautifulSoup یک کتابخانه توکار نیست، قبل از استفاده از آن باید آن را نصب کنیم. برای نصب BeautifulSoup ، دستور زیر را اجرا کنید
|
1 2 3 4 5 6 |
$ apt-get install Python-bs4 # For Linux and Python2 $ apt-get install Python3-bs4 # for Linux based system and Python3. $ easy_install beautifulsoup4 # For windows machine, Or $ pip instal beatifulsoup4 # For window machine |
پس از اتمام نصب، ما آماده هستیم تا چند نمونه را اجرا کنیم و Beautifulsoup را با جزئیات کاوش کنیم ،
خروجی
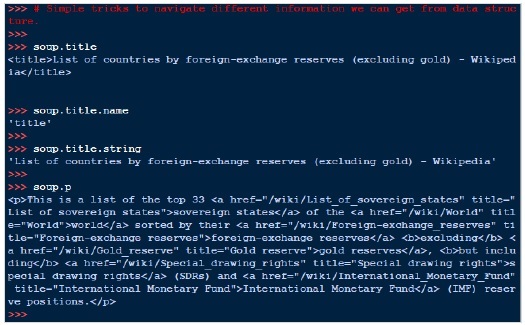
در زیر چند روش ساده برای حرکت در آن ساختار داده آمده است –
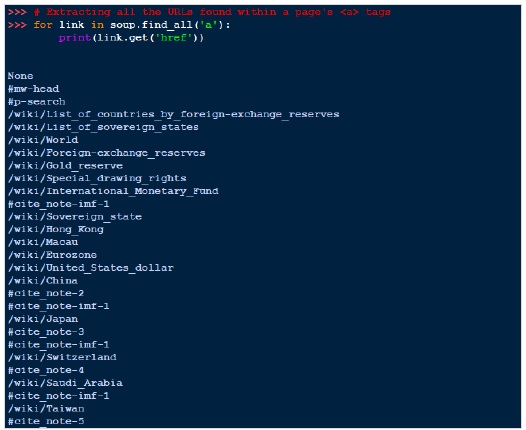
یکی از وظایف رایج استخراج تمام آدرس های اینترنتی موجود در تگ های <a> یک صفحه است –
یکی دیگر از وظایف رایج استخراج تمام متن از یک صفحه است
لیست جلسات آموزش برنامه نویسی شی گرا در پایتون
- آموزش برنامه نویسی شی گرا در پایتون
- آموزش مقدماتی برنامه نویسی شی گرا در پایتون
- آموزش راه اندازی محیط برنامه نویسی شی گرا در پایتون
- آموزش ساختار داده برنامه نویسی شی گرا در پایتون
- آموزش بلوک ها در برنامه نویسی شی گرا در پایتون
- آموزش میانبرها در برنامه نویسی شی گرا در پایتون
- آموزش وراثت و چند شکلی در برنامه نویسی شی گرا در پایتون
- آموزش الگوی طراحی در برنامه نویسی شی گرا در پایتون
- آموزش ویژگی های پیشرفته در برنامه نویسی شی گرا در پایتون
- آموزش فایل ها و رشته ها در برنامه نویسی شی گرا در پایتون
- آموزش مدیریت استثنا در برنامه نویسی شی گرا در پایتون
- آموزش سریال سازی شی در برنامه نویسی شی گرا در پایتون



.svg)
دیدگاه شما